See also the fleetcommand-agent Release Notes.
-
Kubernetes - see the Kubernetes compatibility chart
Domino Nexus
Domino Nexus is a single pane of glass that lets you run data science and machine learning workloads across any compute cluster — in any cloud, region, or on-premises. It unifies data science silos across the enterprise, so you have one place to build, deploy, and monitor models.
See these topics for complete details:
Some Domino features work differently in the Nexus hybrid architecture than they do in other types of deployments:
-
Domino Nexus introduces the concept of data locality.
Data may only be available in certain data planes due to geographic access restrictions or simply the cost of moving data between data centers. Domino automatically mounts all available data for a given data plane.
-
These features are only available in the
Localdata plane (hosted in the control plane):-
Model APIs
-
Apps
-
Datasets
-
Trino data sources
-
Other types of data sources can be accessed on both the
Localand remote data planes, but functionality on remote data planes is in Preview. Functionality for restricting data sources to specific data planes is under development. External Data Volumes (EDVs) are the primary method for accessing large data sets, and have a first-class notion of data locality; see Associate Data Planes with EDVs.
-
-
When you launch an execution, hardware tiers are grouped by data plane. Select a tier in the data plane in which the execution should run. The
Localdata plane corresponds to running the execution in the Domino control plane cluster. -
For compute clusters that include a user interface, the UI link is available only if the data plane is configured for workspaces. See Enable A Data Plane For Workspaces. If the data plane is not configured for workspaces, clusters can still be used with jobs, but the user interface link is disabled.
Experiment management
Domino experiment management leverages MLflow Tracking to enable easy logging of experiment parameters, metrics, and artifacts, while providing a Domino-native user experience to help you analyze your results. MLflow runs as a service in your Domino cluster, fully integrated within your workspace and jobs, and honoring role-based access control. Existing MLflow experiments works right out of the box with no code changes required.
See Experiments for complete details.
|
Note
|
|
Domino Code Assist
Domino Code Assist automatically generates Python and R Code for common data science and analysis tasks through a simple point-and-click interface.
It helps novice coders quickly become productive in writing R and Python code. For those more familiar with writing code, Code Assist accelerates common data analysis tasks by auto-generating boilerplate code that can be further edited as needed for a project. Code Assist can autogenerate Python or R code for the following tasks:
-
Import data from Cloud stores like Snowflake or Redshift.
-
Transform data with operations like filtering and aggregation.
-
Create and deploy data apps. Code Assist also allows you to create code snippets that can be shared for common tasks.
Code Assist ships standard in Domino 5.5. It can be installed manually in Domino 4.x or later.
Asynchronous Model APIs
Domino Asynchronous Model APIs allow you to host complex inference processing involving workloads such as deep learning predictions, unstructured data transformations, and other similar executions that are computationally intensive and not suitable for synchronous HTTP endpoints.
An Asynchronous Model API queues incoming requests and processes them asynchronously while giving end users an interface to query the status of the processing and fetch the results when complete. For more details, see Long-running inferences and Asynchronous interfaces.
Feature store (public preview)
Domino’s new feature store leverages Feast to streamline and standardize data for machine learning projects. It helps foster reusability, collaboration, and reproducibility by ensuring a single source of truth for calculating features and providing a system of records for computed features. Features can be accessed from Domino workspaces, boosting data scientists' productivity and consistency. In this release, the feature store is a public preview feature.
New Palantir Foundry data connector
Now you can access your Palantir Foundry data store from Domino, using a Starburst-powered connector.
An administrator must create the Palantir Foundry data source before users can access it.
-
When experiment management is enabled (by setting
com.cerebro.domino.workbench.experimentManagement.enabledtotrue), the project menu takes on a new layout:-
Files becomes Code.
-
The Run section becomes Develop, and it includes the Code and Data pages.
-
The Materials section becomes Evaluate, and it now includes the Jobs page.
-
The Activity page becomes a tab on the Overview page.
-
The Scheduled Jobs page becomes a tab on the Jobs page.
5.4 project menu 5.5 project menu 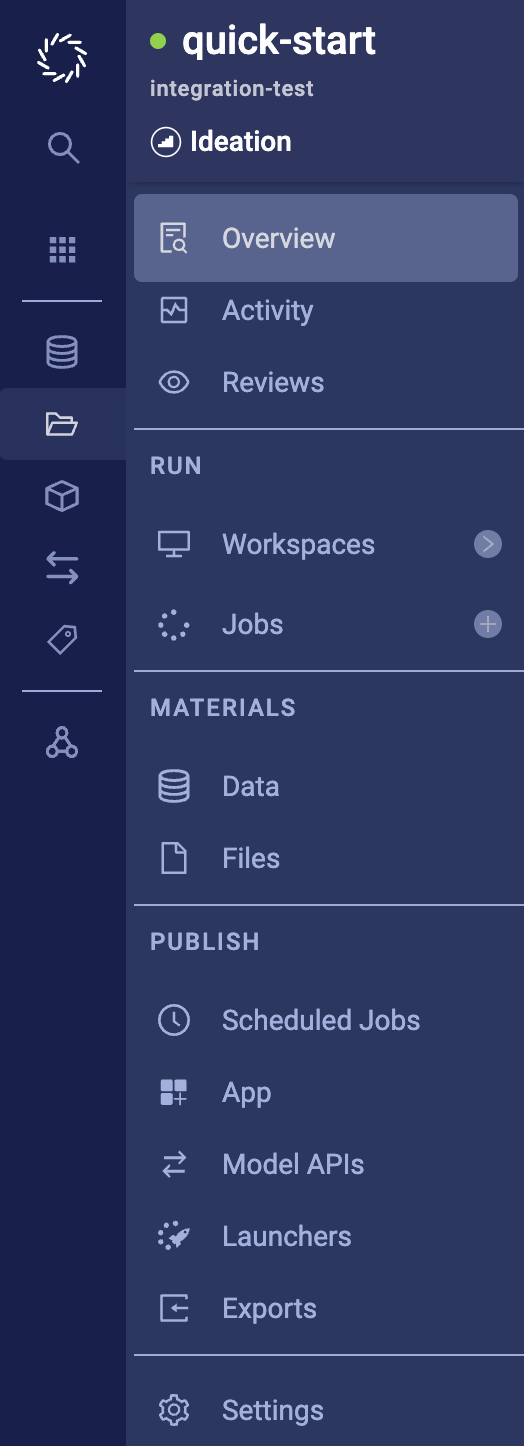
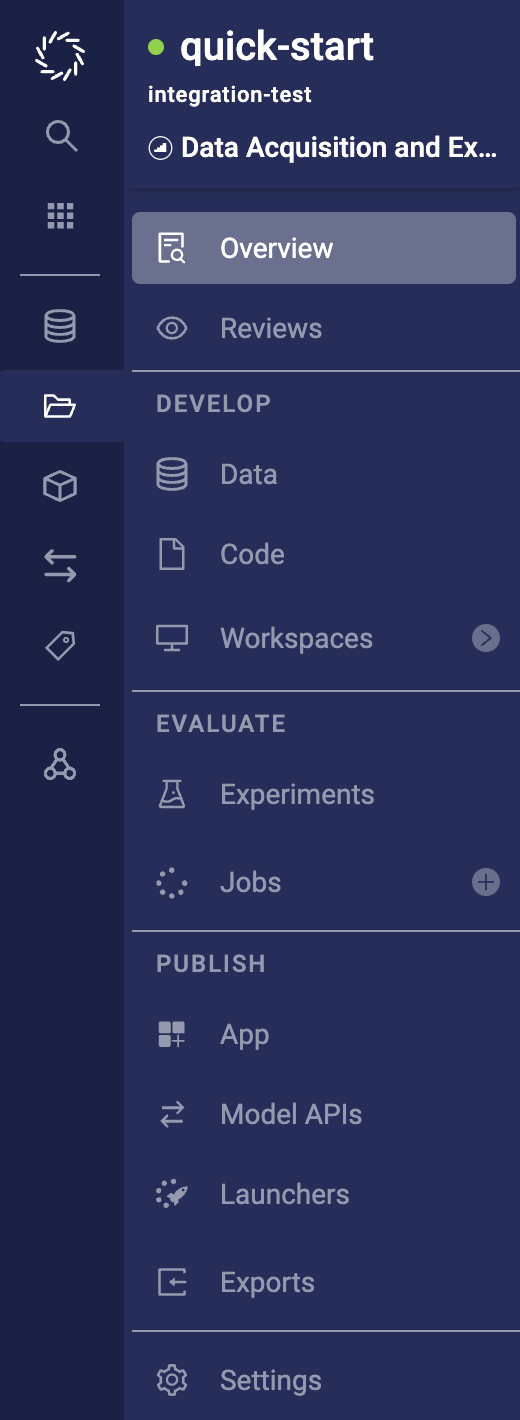
-
-
Git-based Projects are now a General-Availability (GA) feature.
-
Model monitoring improvements
-
Support for EKS version 1.24
This version requires the use of EKS optimized Amazon Linux AMI release 1.24.7-20221222 or later.
-
Keycloak upgraded to version 18
Custom Keycloak script providers (script mappers and script authenticators) are automatically migrated to a different format for compatibility with Keycloak version 18 and above.
As a result, you can no longer see or update script providers code in the Keycloak admin console. Domino automatically migrates existing code and stores it at
/opt/jboss/keycloak/standalone/deployments/keycloak-resources/script_providers.jarin the Keycloak pod(s).See Javascript providers in the Keycloak documentation for further details about this format change. Any new script provider code should be packaged into a JAR file (multiple files can co-exist) and uploaded to the
/opt/jboss/keycloak/standalone/deployments/keycloak-resources/folder. In case of using multiple Keycloak replica pods, it is enough to upload the file to one of them. This action does not require a Keycloak pod restart.
-
Changes to the User Session Count Limiter in Keycloak
You can select either Deny new session or Terminate oldest session as the desired behavior when configuring the User Session Count Limiter in Keycloak.
-
Improve system stability when running a large number (> 1000) of jobs concurrently. See Sizing the Domino platform: Large for more details on how to size resources when running workloads at this scale.
-
The
EnableLegacyJwtToolingfeature flag now defaults tofalsefor new deployments. When existing deployments are upgraded to 5.5.0, the value still defaults totrue.
-
Docker bridge is not supported in Kubernetes 1.24 and above.
-
Domino Admin Toolkit is installed with Domino 5.5.0 and is now an always-on deployment.
As a result it is no longer necessary to use the Admin Toolkit CLI (
toolkit.sh) to install it; it is automatically available even in air-gapped deployments.The Toolkit’s front-end UI is now available permanently at the URL https://<your-domino-url>/toolkit/
The sending of reports generated by Admin Toolkit now has an opt-in/opt-out feature, controlled through the Toolkit UI. The default is to opt in.
The Toolkit UI also includes a button to check for an automatic update to the latest version of the toolkit. For air-gapped deployments the Admin Toolkit CLI can be used to copy the new image to a private repository.
-
Adding model environment variables no longer restarts your model instances. The newly added environment variables take effect on the next model version start.
Updates to the <code>python-domino</code> library:
The DominoSparkOperator test is updated for compute_cluster_properties.
The minimum Python version required is now Python 3.7.
The paths under /u/{ownerUsername}/{projectName}/scheduledruns have been deprecated and were removed in Domino 5.8.0.
-
Metrics publishing is reduced to the minimal number of metrics essential to Domino Model Monitoring operation, to prevent prometheus-adapter OOM errors.
Please review your independent reliance on Kubernetes metrics at the cluster level and validate your upstream source, especially if you run Domino in a cluster environment shared with other applications. This change can be overridden via an upgrade/install path if desired. Please contact Domino Support for any questions or concerns via https://tickets.dominodatalab.com or support@dominodatalab.com.
-
Domino Model Monitor is now compatible with Kubernetes versions 1.21 and above; it no longer stops working after 90 days of uptime in these deployments and it is no longer necessary to periodically restart it.
-
You can now use GitLab subprojects when creating a Git-based project via the Choose a repository option in the Create New Project window.
-
"Other" Git service provider URLs not ending in ".git" no longer fail when you attempt to create a project from a Git repo or add a Git repo to a project.
-
You cannot view the latest raw file. In the navigation pane, go to Files and click a file to view its details. If you click View Latest Raw File, a blank page opens.
-
Running a large number of jobs concurrently (> 1000) can introduce system instability and result in some job failures. We now document how to properly size Domino resources in deployments that expect this level of load. See Sizing the Domino platform: Large.
-
When uploading a large file to the Azure blob store by syncing a workspace, you may encounter a Java Out of Memory error from Azure if the file/blob already exists. To work around this issue, use the Domino CLI to upload the file to the project.
-
Model Monitoring data sources aren’t validated. If you enter an invalid bucket name and attempt to save, the entry will go through. However, you won’t be able to see metrics for that entry because the name points to an invalid bucket.
-
Intermittent inability to schedule DMM jobs in narrow windows. The DMM scheduler has a memory leak that causes it to restart when it approaches the memory limit. This should not occur more than once every few days, and the downtime should be a few seconds at most. This issue is resolved in Domino 5.5.1.
-
In Azure Blob Store deployments, projects with many files may fail to sync through the Domino CLI. To work around this issue, do not disable file locking when prompted by Domino.
-
Domino instances that make use of Azure Blob Storage may experience stalled jobs within projects with many large files.
-
When using Azure Blob Storage for backups, daily backups do not complete successfully and backups are only stored in Azure Files storage. This issue is resolved in Domino 5.6.1.
-
Upgrading Domino from a version below 5.5.0 to version 5.5.0 on Azure AFS may fail if the Keycloak script providers were previously configured on your instance. Contact Domino Support for help. This issue is resolved in Domino 5.7.0.
-
Publishing a new version of a model API as a non-admin user fails if the first model in the project was created by someone else. To address this problem, add the non-admin user as a collaborator to the
prediction_datadataset for that project. This issue is fixed in Domino 5.5.4.
-
If the
nucleus-dispatcherKubernetes pod is restarted (during Domino upgrade, after restarting Nucleus services via the admin central configuration page, after the previous pod crashing, or for some other reason), then existing executions (including workspaces and jobs) may fail. This issue is resolved in Domino 5.5.4.
-
The Status, Active Version, and Owner columns do not appear in the Model API list. This issue is fixed in Domino 5.8.0.
-
Deleting all R variables from memory using
rm(list = ls(al = TRUE))also deletes variables that Domino uses for internal processes. To safely delete variables, userm(list = ls(all = TRUE)[!grepl("^.domino", ls(all = TRUE))])instead."
-
When restarting a Workspace through the Update Settings modal, External Data Volumes are not mounted in the new Workspace. Follow the steps to mount External Data Volumes. This issue is fixed in Domino 5.9.0.
-
Downloading single files from Datasets will fail if the filename contains special characters, including
+and&. As a workaround, remove the mentioned special characters by renaming the file. This issue is fixed in Domino 5.10.0.
-
Spaces in ADLS filenames are not allowed when getting and putting objects in Azure Data Sources with DominoDataR. As a workaround, upgrade to DominoDataR version 0.2.4. This issue is fixed in Domino 5.10.0.
|
Important
| If you are upgrading to this Domino release from a version earlier than Domino 5.3.0, you must put Domino into maintenance mode to avoid losing work. Maintenance mode pauses all apps, model APIs, restartable workspaces, and scheduled jobs. Allow running jobs to complete or stop them manually. |
-
AKS users that provisioned their infrastructure with Domino’s terraform-azure-aks module must apply the changes introduced as of terraform-azure-aks v2.1.2 when upgrading to ensure diagnostic settings are removed.