Use the Starburst/Trino Data Source to connect to an existing Starburst/Trino cluster. Once connected, you can use the Data Source to:
-
Execute queries against the Starburst/Trino cluster using the data stores it’s connected to.
-
Run Starburst/Trino federated queries supported by your Starburst/Trino cluster.
See the list of Trino connectors Trino connectors for supported data stores.
You must have network connectivity between the Starburst/Trino cluster and your Domino deployment.
Domino recommends that you use a Domino Data Source to connect to a Trino instance.
-
From the navigation pane, click Data > Connect to External Data.
-
Select Trino in the Select Data Store dropdown.
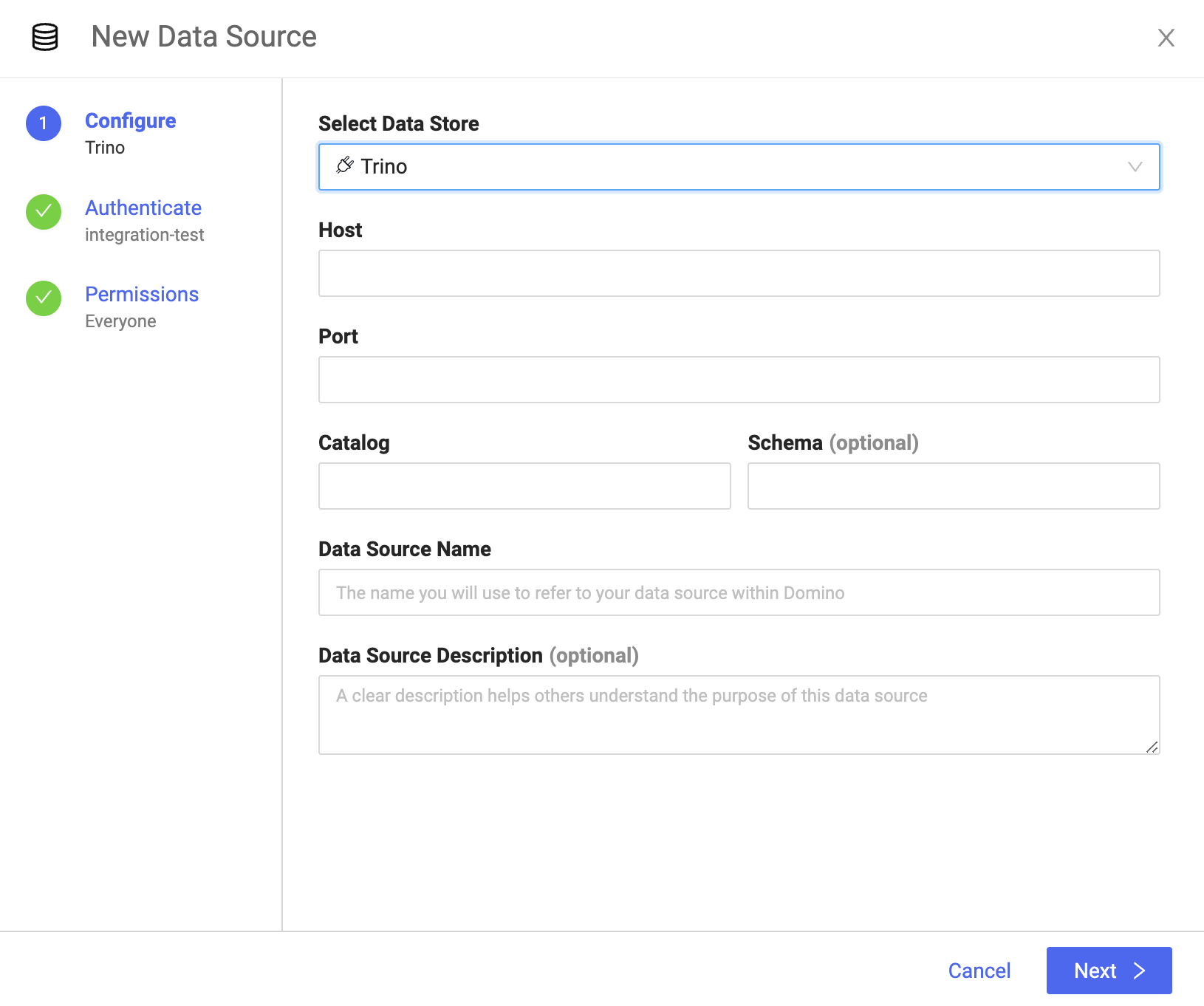
-
Enter the details about your Data Source and click Next:
- Host
-
The URL, hostname, or IP address of your Trino host.
- Port
-
The port number for the connection, such as 443.
- Catalog
-
The name of the Trino catalog where your data is located. For example, if you plan to use the table
hive.test_data.testthen the catalog name ishive. - Optional: Schema
-
The name of the Trino schema to use. For example, if you plan to use the table
hive.test_data.testthen the schema name istest_data. - Data Source Name
-
The name that identifies the Data Source.
- Optional: Data Source Description
-
The purpose for the Data Source.
-
Specify the credentials for authenticating to Trino.
Basic authentication is supported by default. The Domino secret store backed by HashiCorp Vault securely stores the credentials.
-
Click Test Credentials.
-
If the Data Source authenticates, click Next.
-
Select who can view and use the Data Source in projects.
-
Click Finish Setup.
-
After connecting to your Data Source, learn how to Use Data Sources.
-
Share this Data Source with your collaborators.