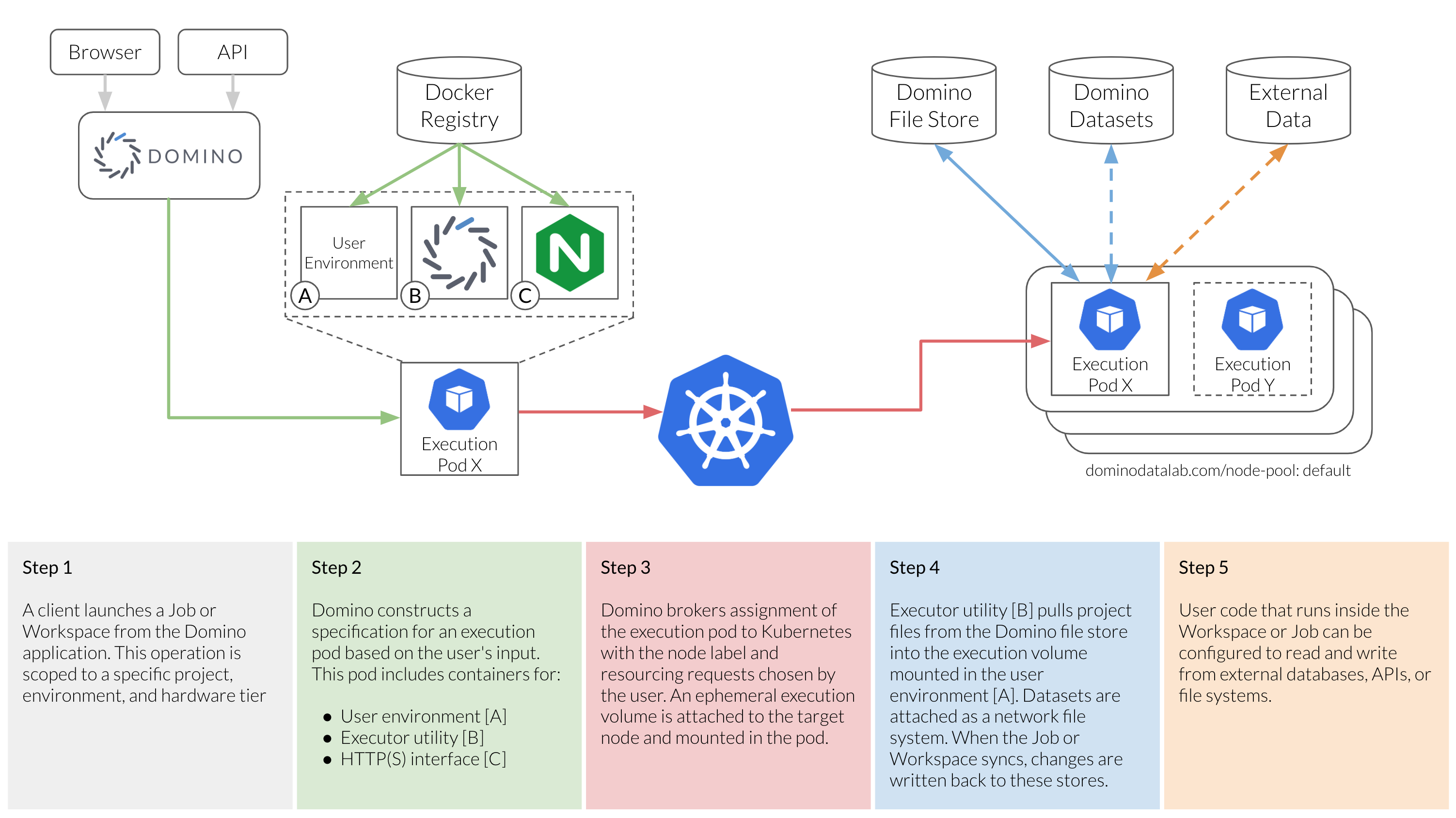
Data moves in and out of Domino executions in the following ways:
Every execution occurs in a project. Based on the Domino File System, the files for the active revision of the project are automatically loaded into the local execution volume for a Job or Workspace. These files are retrieved from the Domino File Store, and any changes to these files are written back to the Domino File Store as a new revision of the project’s files.
You can configure Domino executions to mount Domino datasets for input and output. Datasets are network volumes mounted in the execution environment. Mounting an input Dataset lets executions start quickly. It also gives them access to large quantities of data because the data is not transferred to the local execution volume until user code performs read operations from the mounted volume. Any data written to an output Dataset is saved by Domino as a new snapshot.
User code that runs in Domino can use Domino data sources or third-party drivers to interact with external databases, APIs, and file systems to which the Domino-hosting cluster can connect. Users can read and write from these external systems, and they can import data into Domino from such systems by saving files to their project writing files to an output Dataset.
The following diagram shows the series of operations that happens when a user starts an execution (Job or Workspace) in Domino, and illustrates when and how various data systems can be used.