NVIDIA DGX systems can run Domino workloads if they are added to your Kubernetes cluster as compute (worker) nodes. This topic covers how to setup and add DGXes to Domino.
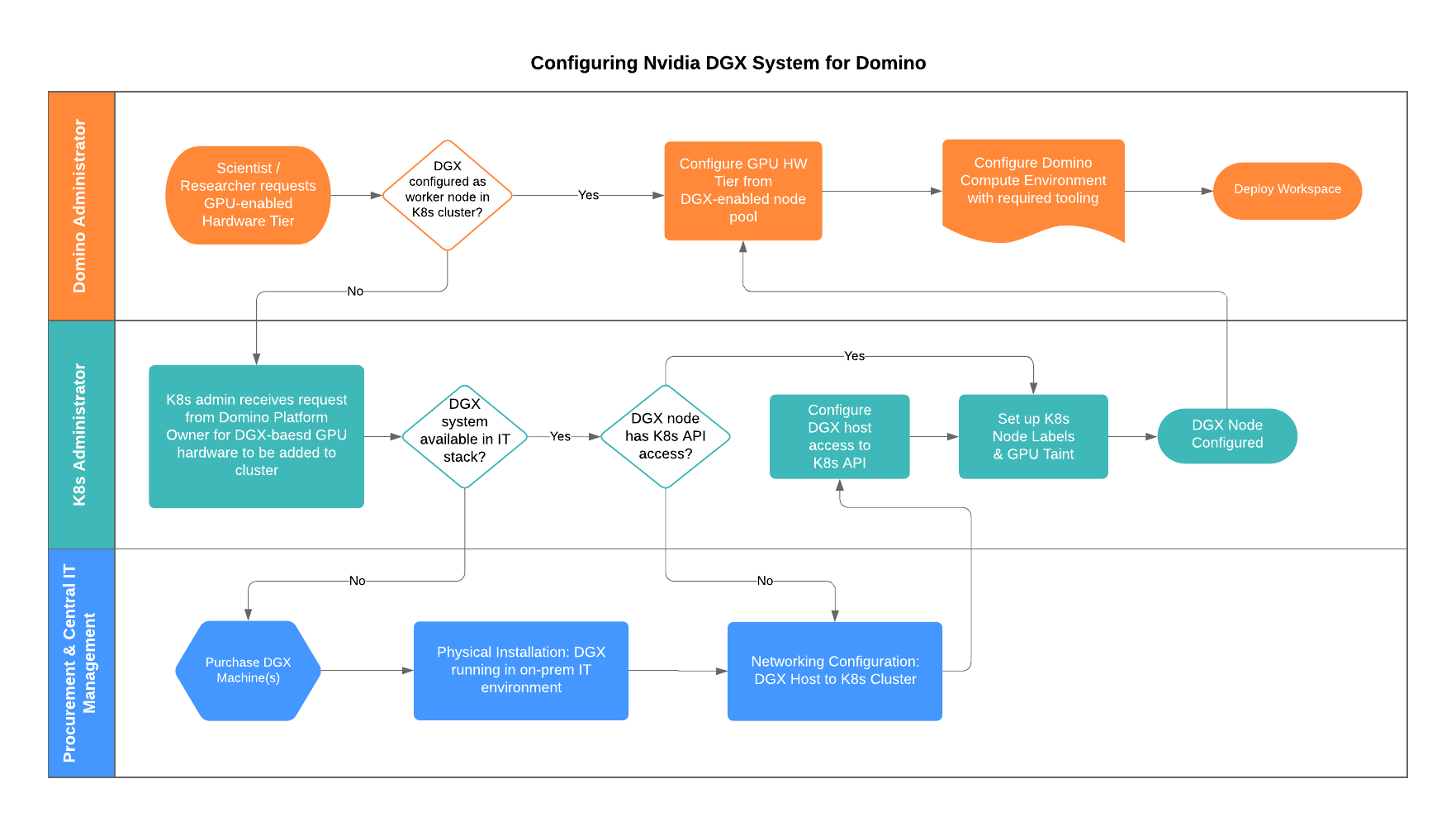
The flow chart begins from the top left, with a Domino end user requesting a GPU tier.
If a DGX is already configured for use in Domino’s Compute Grid, the Domino platform administrator can define a GPU-enabled Hardware Tier from within the Admin console.
The middle lane of the flow chart outlines the steps required to integrate a provisioned DGX system as a node in the Kubernetes cluster that is hosting Domino, and subsequently configure that node as a GPU-enabled component of Domino’s compute grid.
The bottom swim lane outlines that, to leverage a NVIDIA DGX system with Domino, it must be purchased and provisioned into the target infrastructure stack hosting Domino.