Users in Domino assign their executions to Domino Hardware Tiers. A hardware tier defines the type of machine a job will run on, and the resource requests and limits for the pod that the Run will execute in. When configuring a hardware tier, you will specify the machine type by providing a Kubernetes node label.
You must create a Kubernetes node label for each type of node you want available for compute workloads in Domino, and apply it consistently to compute nodes that meet that specification. Nodes with the same label become a node pool, and they will be used as available for Runs assigned to a Hardware Tier that points to their label.
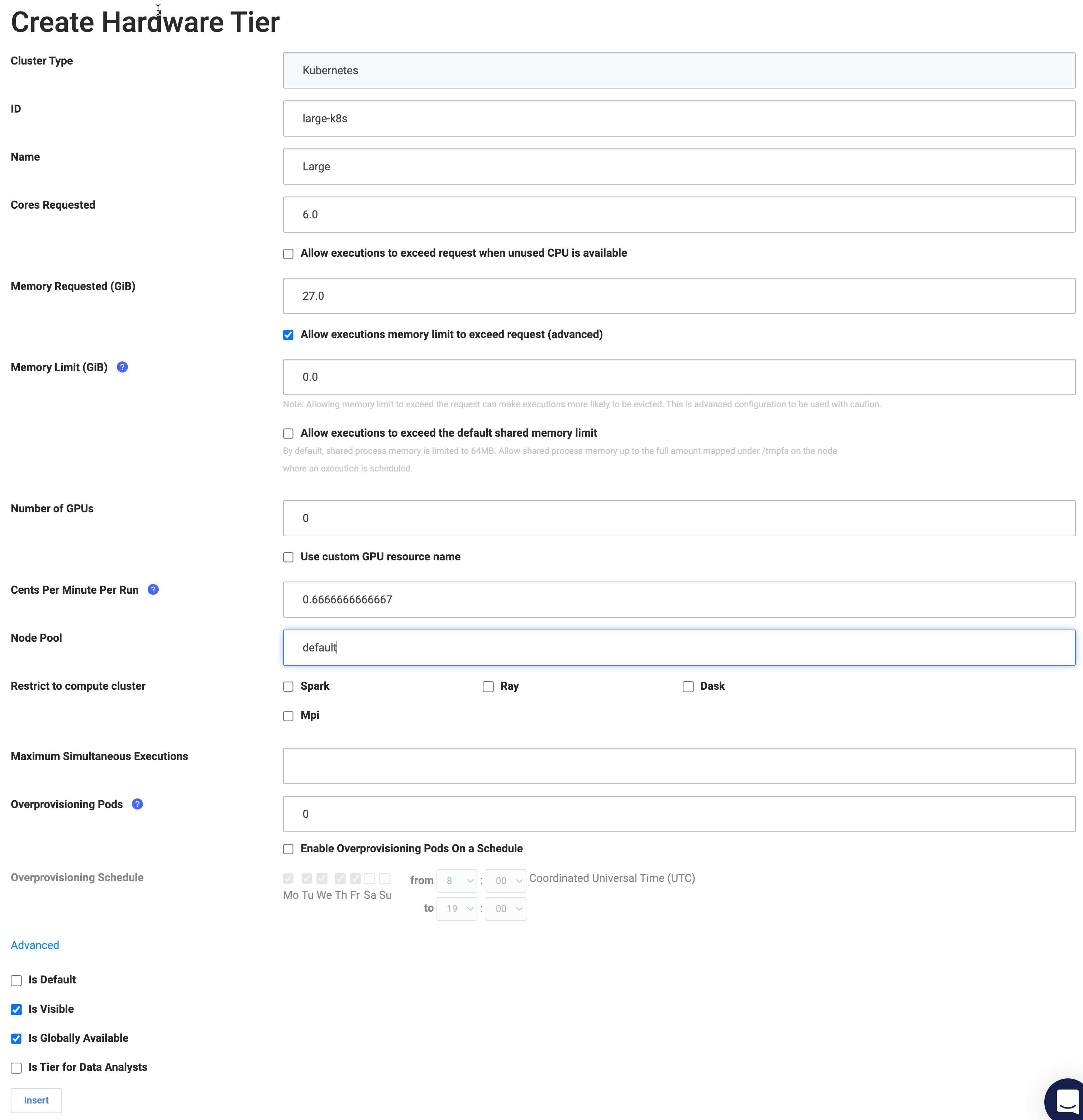
Which pool a Hardware Tier is configured to use is determined by the value in the Node Pool field of the Hardware Tier editor.
In the screenshot below, the large-k8s Hardware Tier is configured to use the default node pool.
The diagram that follows shows a cluster configured with two node pools for Domino, one named default and one named default-gpu.
You can make additional node pools available to Domino by labeling them with the same scheme: dominodatalab.com/node-pool=<node-pool-name>.
The arrows in this diagram represent Domino requesting that a node with a given label be assigned to a Run.
Kubernetes will then assign the Run to a node in the specified pool that has sufficient resources.
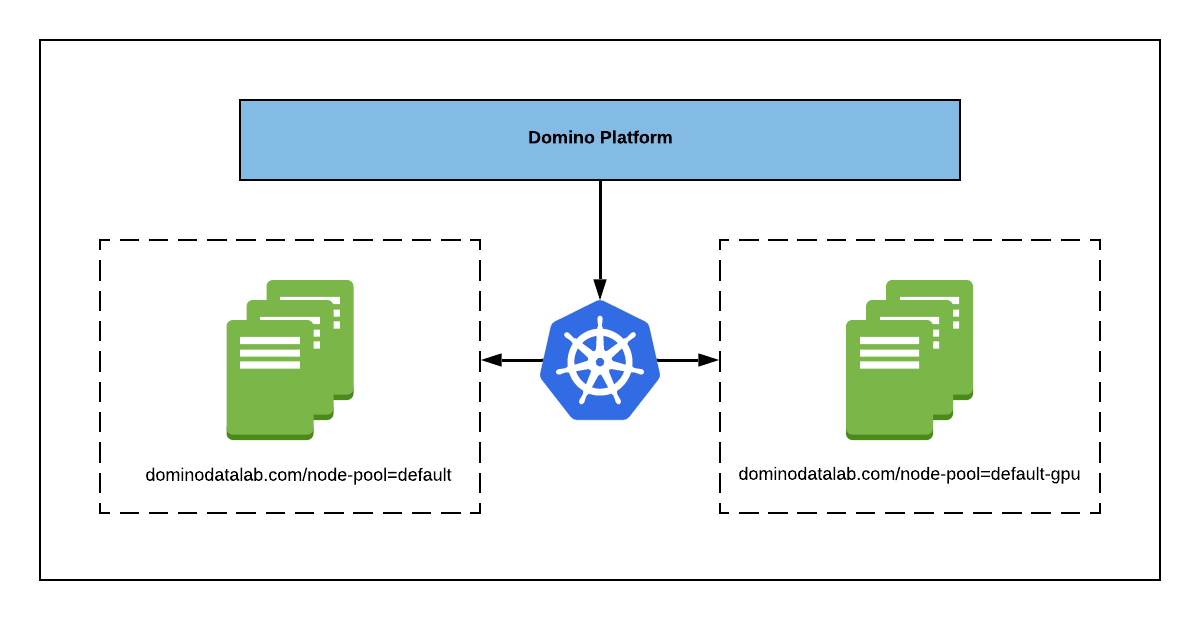
By default, Domino creates a node pool with the label dominodatalab.com/node-pool=default and all compute nodes Domino creates in cloud environments are assumed to be in this pool.
In cloud environments with automatic node scaling, you will configure scaling components like AWS Auto Scaling Groups or Azure Scale Sets with these labels to create elastic node pools.